This analysis draws on a recent piece published by writers at Arize AI, featuring an in-depth conversation with Tobias Leong, CTO and cofounder of Axium Industries. All direct quotes from Leong are sourced from that piece. GAIG analysis and editorial positions are our own.
Key Stats
78% of executives can't confidently pass an AI governance audit in 90 days
Grant Thornton 2026
5 distinct agent maturity stages — most enterprises are at Stage 2 with Stage 4 governance assumptions
Arize AI / GAIG Analysis
6 distinct context layers that require evaluation in production AI agents
GAIG Analysis
Related Reading
Most AI agent teams can ship a working demo in a day. The agent answers questions, calls tools, completes multi-step tasks, and looks impressive in a controlled environment with curated inputs. Then it hits production — real users, messy data, legacy infrastructure, and workflows that evolved over years before the agent existed. That's where things break. And the teams that discover the break from a user complaint rather than their own monitoring program are the ones that evaluated the wrong layer.
The standard evaluation playbook for AI agents focuses on output accuracy. Did the model answer correctly? Did it hallucinate? Did it pass the benchmark? Those questions are reasonable starting points and completely insufficient for production agents. An agent can produce correct-looking outputs while using bad context, retrieving irrelevant or stale data, calling tools in the wrong sequence, or reasoning over a state that doesn't match the actual system it's operating on. The output looks fine. The underlying decision chain is compromised.
A recent piece by writers at Arize AI, built around a conversation with Tobias Leong — CTO and cofounder of Axium Industries, a company building AI agents for industrial supply chain and operations — makes this case with production evidence rather than theory. The argument is simple and consequential: the bottleneck in production AI agents isn't model quality. It's context and evaluation. And most organizations are investing heavily in the former while underbuilding the latter.
"The teams that succeed in production AI will not be the ones with the best model. They will be the ones with the best systems around it."
— GAIG Analysis, drawing on Arize AI production research
Why Output-Only Evaluation Fails for Agents
Traditional models have a relatively contained evaluation surface. Input goes in, output comes out, you measure the output against a ground truth. For static LLM applications this is imperfect but workable. For AI agents it breaks down almost immediately because agents don't operate like that. They plan. They retrieve. They call tools. They maintain state across interactions. They chain decisions across multiple steps where each step affects the next. Output-only evaluation misses every one of those layers.
Tobias Leong described this failure mode with a precision that production teams will recognize immediately. Speaking with writers at Arize AI, Leong noted:
"The models sometimes answer the question that you wish to ask, but not the one you actually asked. And it sounds really confident."
Tobias Leong
CTO & Co-Founder, Axium Industries — via Arize AI
That's not a model problem. The model is doing exactly what it was trained to do — generating a confident, fluent response to the question it inferred from the context it received. If the context was wrong, incomplete, or misaligned with the actual question, the output reflects that misalignment while appearing entirely plausible. Output-only evaluation has no mechanism to detect this. A correct-looking answer to the wrong question scores perfectly on accuracy metrics and fails completely in production.
The production consequences compound. In regulated environments, an agent giving confident wrong answers to compliance questions creates legal exposure. In financial workflows, confident incorrect inventory decisions create operational loss. In healthcare contexts, confident misaligned outputs create patient risk. The failure mode isn't dramatic — it's quietly systematic, building over time as the agent consistently reasons well over bad context.
Failure Mode 1: Confident Irrelevance
The agent answers the question it inferred rather than the one actually asked. Output accuracy metrics score it well. Production behavior is misaligned.
"The models sometimes answer the question that you wish to ask, but not the one you actually asked. And it sounds really confident."
— Tobias Leong, via Arize AI
Failure Mode 2: Model Upgrade Trap
Teams responding to production failures by upgrading the model discover the problem persists. The issue was context, not capability.
"We swapped in a new model, and it actually did nothing … because of insufficient context."
— Tobias Leong, via Arize AI
Failure Mode 3: Silent Evaluation Absence
Without a way to measure what the agent actually did and why, performance degrades invisibly. No alert fires. No threshold crosses. The agent just gets worse.
Leong draws the line clearly: "Evaluation … transcends something that seems to be working into something that actually works."
— via Arize AI
What Context Evaluation Actually Means
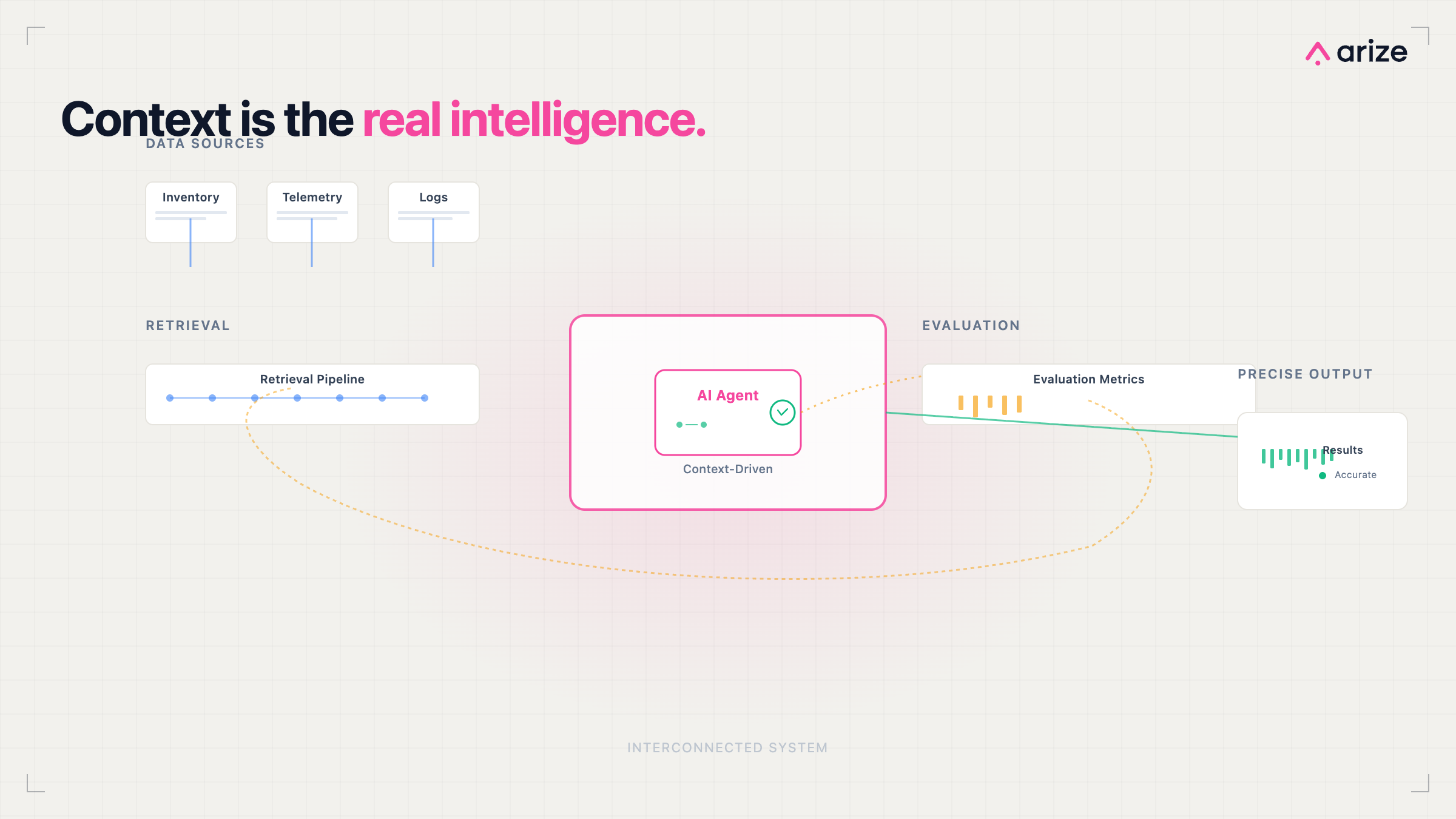
Context evaluation means measuring everything an agent uses to make a decision — not just what it produced. In production systems, context is far more than the system prompt. It encompasses the full information environment in which the agent operates, and each component of that environment is a distinct failure surface requiring its own evaluation approach.
📥 Prompt & Context Construction
Is the agent receiving the right information at the right level of specificity? Poorly constructed prompts produce misaligned reasoning regardless of model quality.
🔍 Retrieval Quality & Relevance
Is the retrieval pipeline returning data that's accurate, current, and relevant to the actual task? Stale or irrelevant retrieval produces confident wrong answers.
🔧 Tool Usage & Execution Paths
Is the agent calling the right tools in the right sequence? Tool call correctness is a distinct evaluation dimension that output metrics don't capture.
🧠 Memory & State Management
Is the agent carrying accurate state across interactions? Memory corruption or staleness creates compounding errors across multi-step workflows.
⛓️ Decision Chains & Reasoning Steps
Can you trace every step from input to output? Without reasoning chain visibility, failures are impossible to diagnose and repeat failures are inevitable.
🏭 Domain-Specific Constraints
Does the agent operate within the rules, constraints, and logic of the specific domain it's deployed in? Generic evaluation misses domain-specific failure modes.
Axium Industries builds agents for industrial environments — manufacturing, logistics, oil and gas, retail. These are high-stakes operational contexts where a wrong inventory replenishment decision has direct financial and operational consequences. The writers at Arize AI note that Leong's team had to achieve a specific and demanding standard: producing the right answer consistently and under uncertainty, not just most of the time in test conditions.
"You need to be very certain that a certain event should be happening. In an example of an inventory replenishment, you need to ensure that you don't have SKUs in the warehouse. You have to really get it right."
Tobias Leong
CTO & Co-Founder, Axium Industries — via Arize AI
The insight that Axium developed from this requirement is one of the most practically valuable in the piece: separate retrieval from reasoning. Don't ask the model to remember facts — give it a pipeline that retrieves grounded data from source systems, then let the model reason over that data. As Leong describes his mental model: LLMs as reasoning engines, not data sources. Once that separation is made, a significant class of context errors disappears because the model is no longer responsible for recalling what it may not accurately know.
How to Implement Context Evaluation in Production
Context evaluation is not a single metric. It's an evaluation program with distinct components for each layer of the agent's context. The Arize AI piece, drawing on Axium's production experience, outlines what an operational evaluation loop actually requires — and what most teams are missing.
Core Components
Task success measurement. Not output quality, task completion. Did the agent accomplish the actual goal? This requires defining success criteria at the task level before deployment, not inferring them from output review after the fact.
Tool call correctness tracking. For every tool invocation, was the right tool called, with the right parameters, at the right point in the execution chain? Tool call errors are invisible in output-only evaluation and common in production multi-tool agents.
Consistency across variations. Does the agent produce consistent outcomes when the same task is presented with slight input variations? Inconsistency signals fragile context handling rather than genuine task understanding.
Edge case behavior testing. Systematic testing against known edge cases in the deployment domain. Axium built these from domain expert knowledge — scenarios that wouldn't appear in standard benchmarks but occur routinely in industrial operations.
Golden dataset evaluation. Domain experts define representative scenarios and expected outcomes. These datasets capture the actual complexity of the deployment context — not synthetic examples designed to make the model look good. Regression detection against these datasets is what catches degradation before users do.
End-to-end tracing. Every step of every agent session captured — model calls, tool invocations, retrieved context, reasoning steps, outputs. Without full trace visibility, diagnosing failures requires reconstruction from incomplete records. With it, every failure is immediately inspectable.
Axium initially built its own evaluation and observability infrastructure. As their systems matured, the maintenance overhead of that infrastructure began competing with actual customer-facing work. The writers at Arize AI describe how Axium evaluated third-party options, ultimately moving to Arize Phoenix and the broader Arize AX platform for production-grade tracing, evaluation, and monitoring. The decision was about focus — building infrastructure slowed down work on the problems that actually differentiated the product.
The broader lesson, as the Arize piece frames it clearly, is that evaluation needs to be treated as infrastructure rather than an afterthought. Organizations that treat evaluation as a pre-deployment checklist and then turn it off are the ones discovering production failures from external signals rather than internal ones.
"Evaluation … transcends something that seems to be working into something that actually works."
Tobias Leong
CTO & Co-Founder, Axium Industries — via Arize AI
Why This Pattern Keeps Showing Up
Output-only evaluation persists because it's easy to implement and it maps to how most teams learned to evaluate software. You have an input, you have an expected output, you measure the distance between actual and expected. That mental model works for deterministic systems. AI agents are not deterministic systems — they're probabilistic reasoning engines operating over dynamic context in production environments that change continuously.
78% of business executives lack strong confidence they could pass an independent AI governance audit within 90 days.
The evaluation gap is part of why. Organizations can't demonstrate agent reliability they didn't build a measurement program around. Audit readiness and production reliability both require the same foundational layer: systematic context evaluation.
The pattern Leong describes — teams chasing model upgrades when production agents underperform — reflects the same instinct. Model quality is visible and marketable. Context quality is invisible and operational. When an agent underperforms, upgrading the model is the action that feels decisive. It produces a procurement decision, a deployment, an announcement. Building a retrieval pipeline evaluation program, defining golden datasets with domain experts, and implementing end-to-end tracing produce none of that — but they fix the actual problem.
"We swapped in a new model, and it actually did nothing. It just raises your costs, but it doesn't actually do anything more, because of insufficient context."
Tobias Leong
CTO & Co-Founder, Axium Industries — via Arize AI
This connects directly to the broader AI monitoring signal gap GAIG has covered in depth. Organizations with monitoring dashboards that capture output quality metrics are measuring the layer furthest from the source of failure. The signals that matter most in production agents — retrieval relevance, tool call correctness, reasoning chain integrity, context completeness — are the ones most monitoring programs aren't built to surface. The dashboard is full of data that isn't the data that matters.
What Has to Change for Governance and Monitoring Teams
The shift from output-only to context-aware evaluation is not a tool procurement decision. It's a program design decision that affects how governance teams define risk, how monitoring teams configure signals, and how security teams assess what agents are actually doing in production. All three have implications for how organizations evaluate and select the platforms they use to govern agentic AI.
Governance Teams
Require context evaluation plans before agent deployment approval
Define task success criteria as governance artifacts, not engineering afterthoughts
Mandate golden dataset creation with domain experts as part of the deployment process
Include retrieval pipeline review in third-party AI vendor assessments
Monitoring Teams
Configure signal capture at the context layer, not just the output layer
Implement end-to-end tracing for every agent session in production
Build regression detection against golden datasets as a continuous monitoring function
Alert on tool call anomalies, not just output quality degradation
Security Teams
Treat retrieval pipelines as privileged data access surfaces requiring access control review
Monitor tool invocation patterns for behavioral drift against established baselines
Require trace visibility as a security control for agents with production system access
Include context scope in agent risk classification
Platform Evaluation
Ask vendors specifically what context-layer signals they capture, not just output metrics
Require demonstration of end-to-end agent tracing in the production environment
Evaluate golden dataset integration as a first-class platform capability
Assess regression detection capabilities before purchasing
The Arize piece includes an agent maturity model that's worth mapping directly to governance readiness — because the stages of technical maturity correspond precisely to stages of governance visibility.
Stage | Technical Focus | Governance Visibility | Evaluation Capability |
|---|---|---|---|
Stage 1 Prototype | Prompting | None — no production behavior visible | Manual spot-check only |
Stage 2 Contextualized | Data and tools | Partial — context sources defined but not evaluated | Output accuracy only |
Stage 3 Evaluated | Measurement | Emerging — task success and context quality being measured | Golden datasets, task success metrics |
Stage 4 Observable | Tracing | Operational — full execution chain visible and auditable | End-to-end tracing, regression detection |
Stage 5 Production-Ready | Reliability & iteration | Comprehensive — context, behavior, and decision chains fully governed | Continuous evaluation as infrastructure |
Most enterprise agents are operating at Stage 2 while their governance programs assume Stage 4 visibility. That gap — between what the agent is doing and what the governance program can see — is where production failures incubate.
"The question I ask every organization evaluating an agent platform is not what the platform measures. It's whether the platform can tell you why the agent made the decision it made — at the context level, not just the output level. Most can't. And that's the gap that shows up in production six months later."
Nathaniel Niyazov
CEO, GetAIGovernance.net
Looking for platforms that deliver context-aware agent observability, end-to-end tracing, and production-grade evaluation infrastructure? Browse Model Observability, AI Runtime Controls, and AI Risk & Controls in the GAIG marketplace — or submit an inquiry and we'll match you with vendors based on your specific agent evaluation requirements.
Our Take
AI Monitoring Take
The Arize AI piece, grounded in Axium Industries' production experience across some of the most operationally demanding environments AI agents are deployed in, makes a case that the enterprise AI governance community needs to hear more clearly: context evaluation is not a nice-to-have observability feature. It's the foundational measurement layer that determines whether your agent governance program has any signal worth acting on.
Output accuracy tells you the agent produced a plausible answer. Context evaluation tells you whether the agent was operating on accurate information, using the right tools, reasoning over a valid state, and following the execution path you intended. Those are different questions. The first sounds like an evaluation question. The second is a governance question — and it's the one that matters when something goes wrong in production.
The teams Leong describes at Axium — who went to offshore supply bases, ships, and warehouses to understand the actual decision environment before building agents into it — represent a level of domain intelligence that most enterprise agent deployments don't invest in. That domain knowledge becomes the foundation for golden datasets, which become the foundation for meaningful evaluation, which becomes the foundation for production reliability. The investment chain runs from domain understanding through evaluation infrastructure to reliable governance. Shortcut any link and the chain breaks.
For governance and monitoring teams evaluating platforms right now: the right question to ask any model observability vendor is not what metrics they capture. It's whether they can surface the context the agent used to make a specific decision, in a specific session, at a specific point in time — and produce that as auditable evidence. That capability is what separates a monitoring dashboard from a governance program.


